
Analýza obrázků a rozpoznání textu v O365
- Posted by Jana Babáčková
- On 6.8.2018
- 0
Představte si na chvíli, že pracujete třeba v účtárně a máte na stole 47 došlých faktur ke zpracování. To je na celý den! Jak by se Vám líbilo mít je uložené v počítači, převedené do formátu .pdf s informacemi o odběrateli, bankovním účtu a zboží, čekající na schválení během několika minut? Nebo můžete být na chvíli automechanikem, ke kterému přijede zákazník, kterého určitě někde v té databázi máte, jen ten správný záznam najít… Proč opisovat SPZ ručně na papír a ťukat čísla do počítače v kanceláři, když ji můžete vyfotit mobilem, odeslat a rovnou z mobilu procházet historii oprav? Po přečtení následujícího článku zjistíte, že O365 opravdu může pracovat za Vás a že jste vysněné “kanceláři bez papíru” zase o něco blíž.
Office 365 spolu s nástrojem Microsoft Flow pro automatizaci firemních procesů nově nabízí sadu akcí pro automatické rozpoznávání textu, obrazu a hlasu, které může využívat každý bez ohledu na plán, protože jde o službu navíc. To jediné co k tomu potřebujete je sada konektorů pro Microsoft Flow z rodiny „Cognitive Services“ nazvaná „Computer Vision“, které se postarají o veškerou analýzu dat bez jediného kousku kódu. Bohužel, bez poplatku se to neobejde – zdarma je Vám většina “Cognitive Services” k dispozici pouze po dobu 7 dní, což je docela málo.
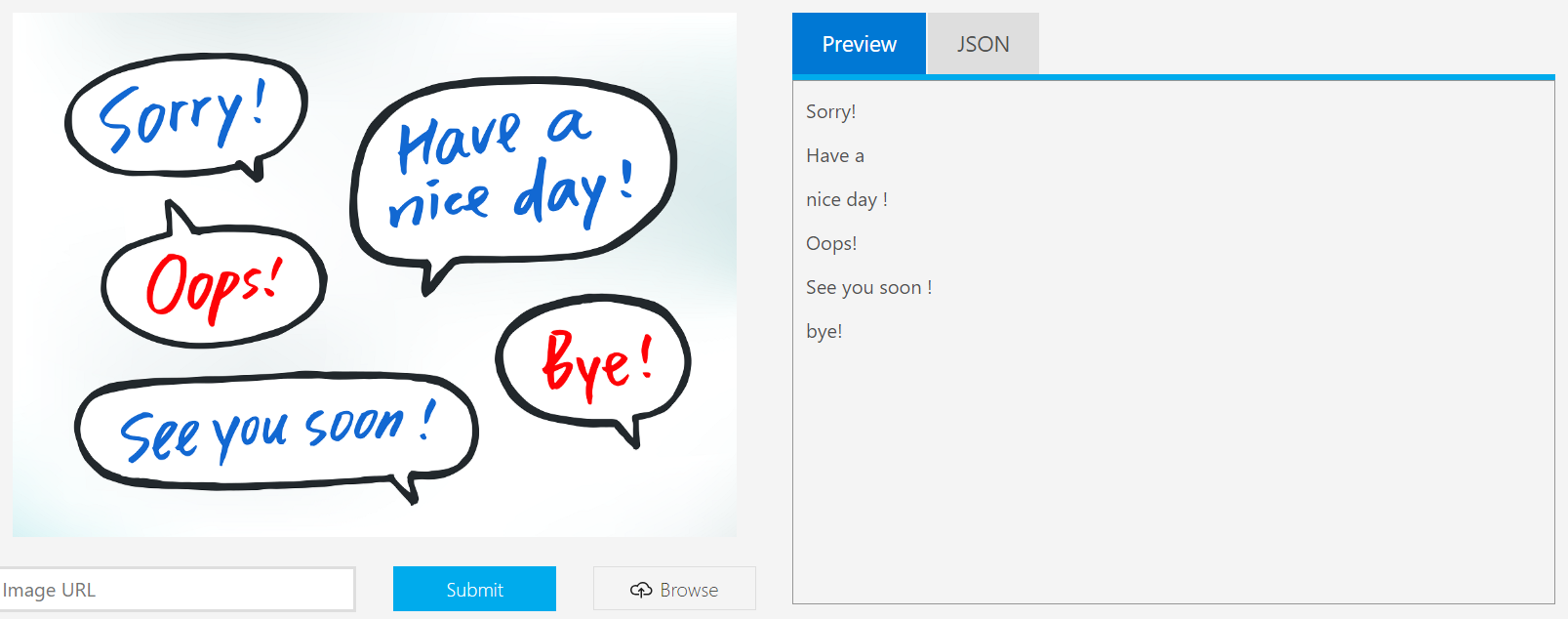
Co je to za službu a jaké akce nabízí? Computer Vision je „cloud-based“ sada nástrojů, procedur a algoritmů sloužících pro zpracování obrazu nebo textu dostupná přes REST API. Když to hodně zjednoduším, tak by se dalo říct, že stačí jen poslat vybraný obrázek na tu správnou adresu a zpátky se Vám vrátí všechny potřebné informace, které o něm chcete mít… Tedy například druh obrázku (černobílý/barevný, clipart/fotografie…), formát obrázku (JPG, GIF, PNG, BMP), rozlišení (kde se pohybujeme od 40 x 40 do 3200 x 3200), obličej v obrázku nebo nevhodný dospělý obsah obrázku (kde zpět dostaneme souřadnice výskytu), můžeme zmenšit obrázky nebo z nich vyrobit náhledy a dokážeme z obrázku vytěžit text.

A to všechno překvapivě rychle. Obrázek do 100 slov, černý text na bílém pozadí, je vyhodnocený do několika vteřin. OCR rozpozná zhruba 25 jazyků, slova zapsaná horizontálně i vertikálně nebo a v mírném natočení.
Jak to funguje? Na to si možná napíšeme někdy v budoucnu samostatný článek, ale pro ten dnešní stačí vědět, že základem všeho je dobrá databáze. V případě rozpoznání textu například druhů písma nebo jazyků, v případě popisování obrázků pak samotných objektů jako jsou budovy, nábytek, zvířata, stromy, rostliny, věci, planety a tak vůbec. Otočené nebo částečné, zachycené z mnoha různých úhlů a v mnoha různých barvách. A z toho také vyplývají jistá omezení.

Nečekejte moc dobrý výsledek, pokud nahráváte obrázek ručně psaného písma s velkým sklonem, tmavého písma na tmavém pozadí bez jasného kontrastu, fotografii rozmazaných objektů, které ani Vy sami dobře nerozeznáte nebo dokonce fotografie Vašich nových výrobků, které v databázi zatím ani být nemohou. Moc dobře si nepovede ani příliš malý nebo příliš velký obrázek nebo písmo na pozadí se vzorem. Zkusíme si malý test. Jak myslíte, že by dopadl obrázek níže?
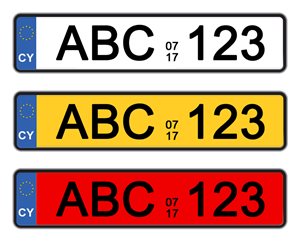
Pokud jste hádali, že se bílá SPZ „přečte“ celá, tak máte pravdu. Trochu horší je to u žluté, tam jsou rozpoznána jen velká písmena a čísla, ale červená nebude zpracována vůbec. Nebo ne zatím. „Computer Vision“ rozhodně nedosahuje kvalit ABBYY Recognition serveru a jemu podobných produktů, ale za mě je to dobrý start (za pěknou cenu).
Teď od teorie k praxi, jdeme si nějaké to Flow vyzkoušet. Pokud se chystáte založit úplně první, nezapomeňte si připravit ID klíč vybrané služby, který jste obdrželi z Azure portálu při registraci. Flow akce „Computer Vision“ ho bude vyžadovat ještě před prvním použitím (ale jen jednou).
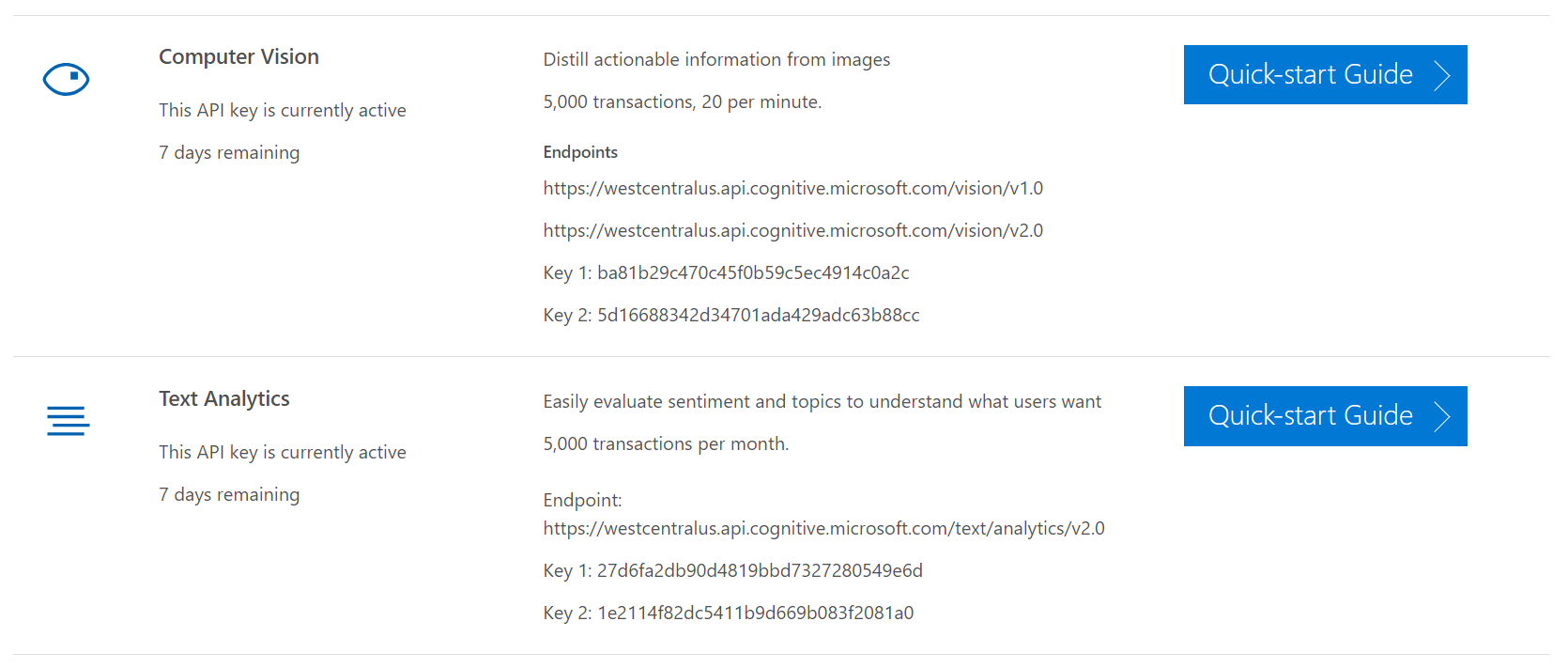
Analýza obrázku
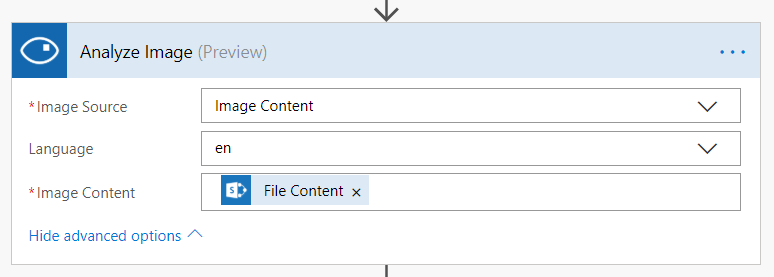
Každý obrázek má nějaké jméno, formát, typ, kvalitu, rozlišení nebo obsah a díky „Computer Vision API“ může mát také popisek doplněný o tagy a nebo rozpoznaný text, může být zmenšený nebo ořezaný a nebo s náhledem. Flow pro analýzu obrázku s popisem a tagy může vypadat následovně:
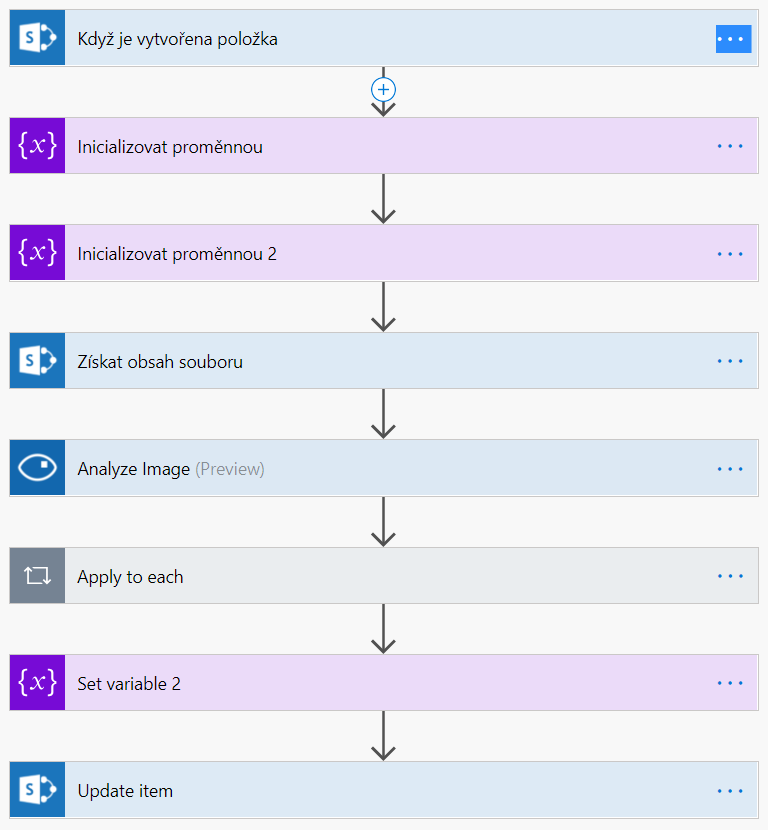
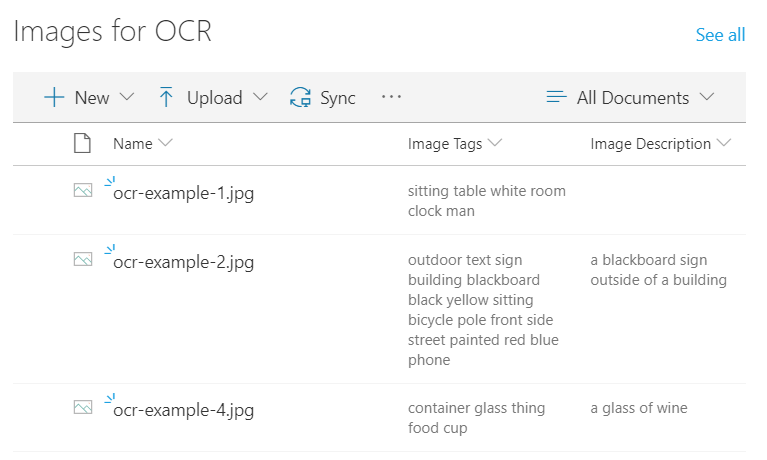
Moje Flow poctivě čeká na každý nový obrázek, který se objeví v jedné obyčejné SharePoint knihovně. Jak se tak stane, odešle ho ke zpracování pomocí „Computer Vision“ akce „Analyze Image“ a pak jen čeká na výsledek. Jedna proměnná je popisek, druhá proměnná jsou tagy, obě mi naplní „Computer Vision“ a já je jen odešlu do mnou založených sloupců. Jako vstup nemusíte řešit nic složitého – zástupná proměnná „File Content“ se o všechno postará. Tak jednoduché to je.
OCR obrázku
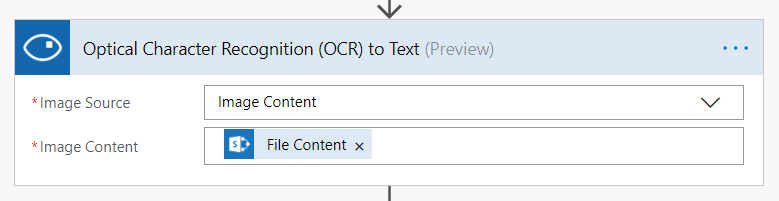
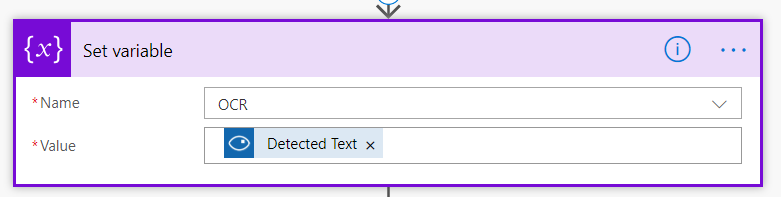
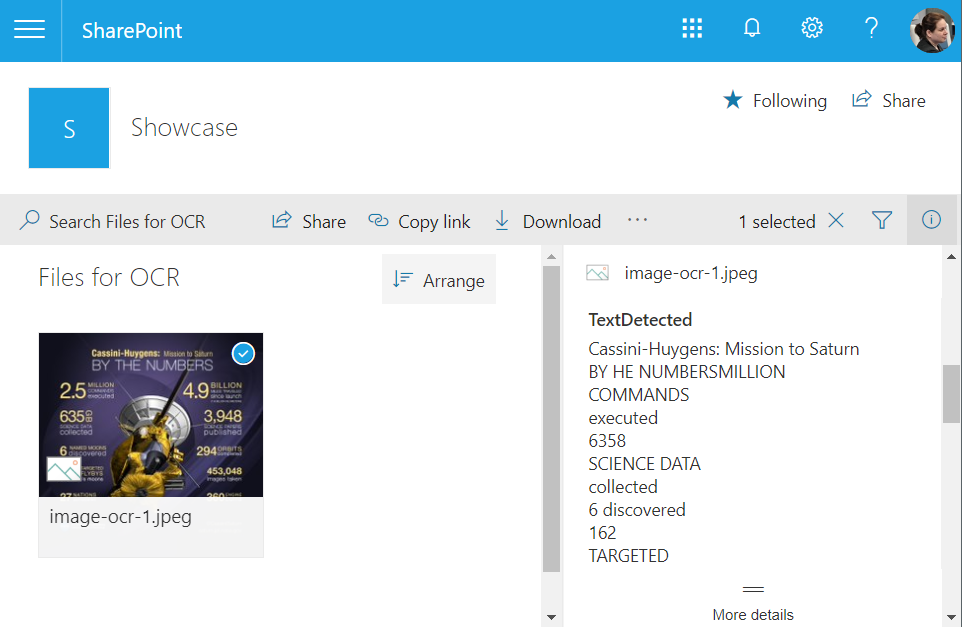
Flow pro OCR obrázku je překvapivě ještě jednodušší, protože tady máme proměnnou jen jednu -„Detected Text“. V té je veškerý rozpoznaný text uložený pohromadě a odřádkovaný. Nezapomeňte proto, že Váš sloupec musí být typu víceřádkový text.

Detail použité akce „Optical Character Recognition (OCR)“ pak vypadá následovně:
Převod formátu souboru
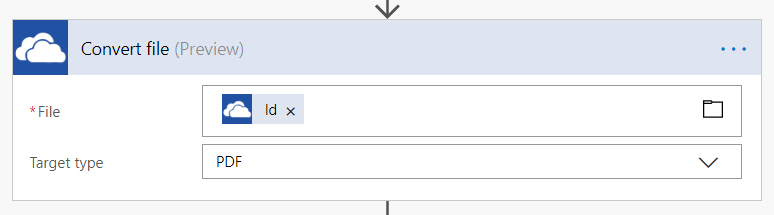
Kdybychom pak měli projít celým příkladem z úvodu článku, potřebujeme ještě konverzi souborů, aby to bylo dokonalé. Převádět můžeme text na .html (a zpět), nebo dokument Wordu na .pdf nebo text na .pdf a to dokonce bez použití „Computer Vision“, jen za pomoci akcí dostupných pro SharePoint, OneDrive nebo e-mail, bez registrací a poplatků. Jednoduché Flow pro převod Word dokumentu do .pdf by mohlo vypadat následovně:

Počkám na nový soubor v knihovně dokumentů, někam si přepošlu verzi k rozpracování, přeformátuji a uložím zpět na původní místo nebo kamkoliv si jen budete přát. Jak je faktura na světě, mohu ji poslat třeba na schválení. Detail akce „Convert File“ je opět „hodně složitý“ a vypadá následovně:
Drobná poznámka na konec: Možná jste si všimli, že celou dobu mluvím o souborech, ale moje Flows pracují s položkami (get item, update item, apod.). Je to trik. Z nějakého důvodu se mi ke zpracovaným souborům těžko vrací metadata do sloupců, když je akce přirazená souboru a ne položce a výsledek je stejný.
Zbývá několik doplňujících informací. „Computer Vision“ má předpřipravené šablony, které můžete použít, ale ve výsledku mi jejich úprava zabrala více času než výroba „na čisto“, tak tu nejsou zmíněné. Vybírat můžete z této nabídky:
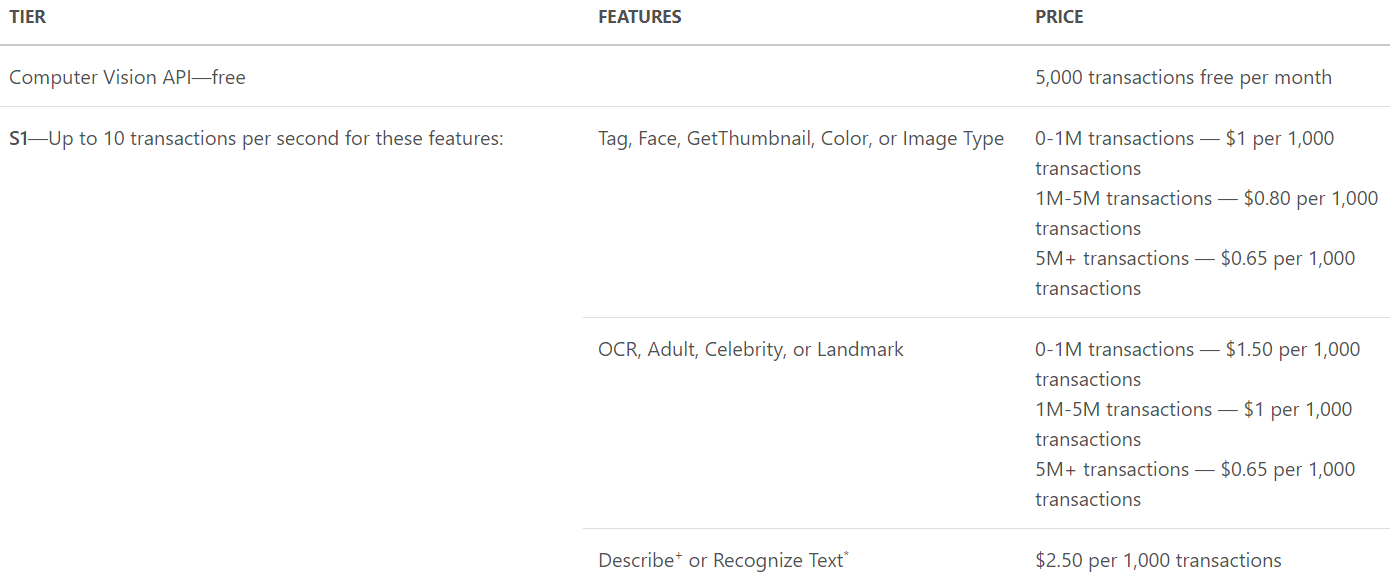
Plány najdete tři, Free (na 7 dní pro většinu služeb), Standard 1 (S1) a Standard 2 (S2), kde standartní plány přináší více transakcí, větší velikost zpracovávaného souboru i více Flow akcí, v průměru za 1 dolar pro 1000 zpracovaných obrázků (transakcí) při celkovém objemu menším než 1 milion. S narůstajícím objemem transakcí pak cena za jednu operaci klesá a stává se výhodnější:
Dokumentaci (v angličtině) najdete na tomto linku.
0 comments on Analýza obrázků a rozpoznání textu v O365